shadowrocket4g网络


GPU分布式训练是指同时利用一台或者多台机器上的 GPU 进行并行计算,使神经网络训练达到更大的batchsize和更快的训练速度,其在大规模网络训练中是十分重要的。本范例基于pytorch的nn.DataParallel和nn.distributedataparallel在多个GPU上切分模型和数据,在训练过程中,每个节点起进程从磁盘加载batch数据,并将它们传递到其节点GPU,每一个节点GPU都有自己的前向过程,然后梯度在各个GPUs间进行All-Reduce。在此过程中,每一层的梯度不依赖于前一层,所以梯度的All-Reduce和后向过程同时计算,能够缓解网络瓶颈。在后向过程的最后,每个节点都得到了平均梯度,这样模型参数保持同步。最终多节点协同训练一个高精度的神经网络模型,本范例实现基于ImageNet图像识别的resnet18模型。
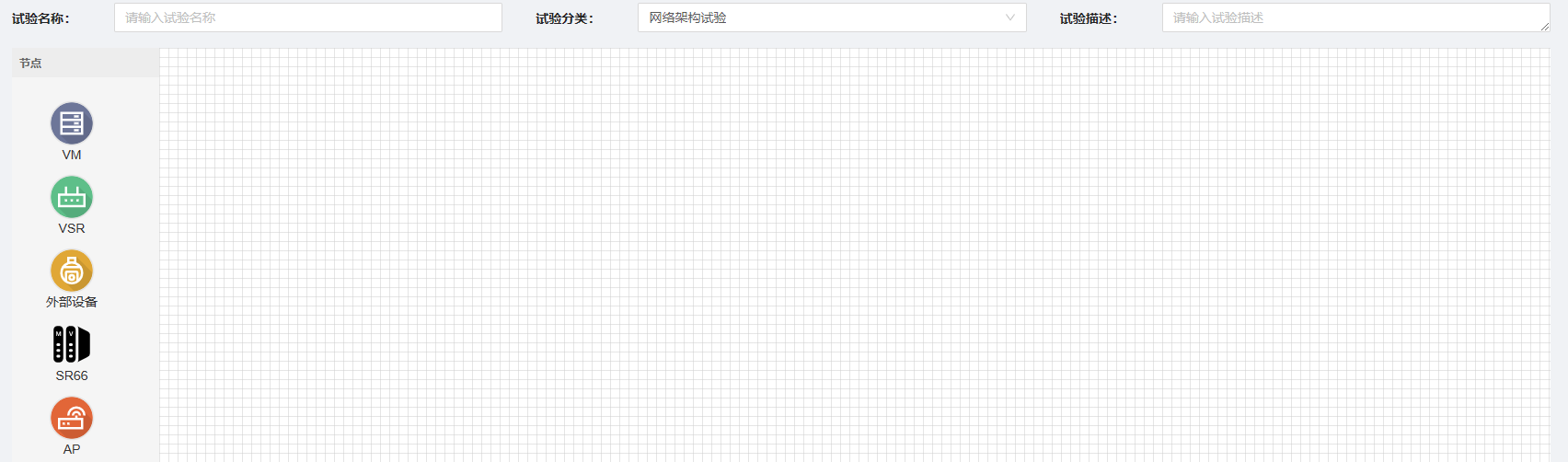
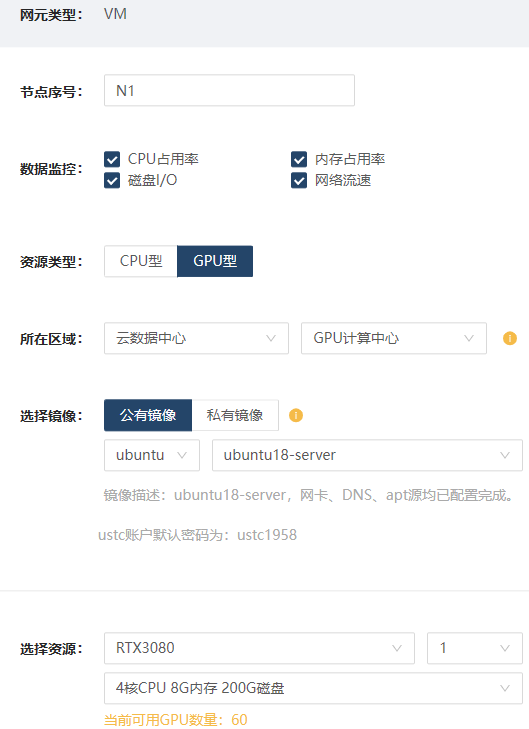
点击下一步开始资源配置。将左侧“VM”拖动到右侧网格区域创建新的节点。首先创建GPU型节点N1:所在区域选择“云数据中心”-“GPU计算中心”镜像选择“公有镜像”—“Ubuntu”—“ubuntu18-server”选择资源选择为“RTX3080” —“4核CPU 8G内存 200G磁盘”,其余配置无需更改,配置完成后点击“保存并复制节点”以增加相同配置的其他节点,至少配置两个节点,这里配置3个节点。
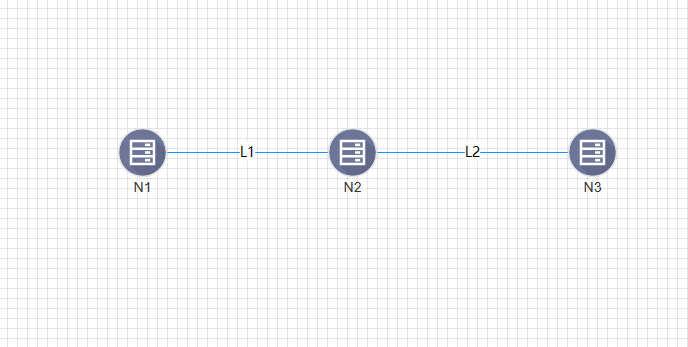
将鼠标悬浮在网格中界点上方,点击节点周围红色小圆圈并拖动与其他节点相连,右侧弹出链路信息,带宽选择10Mbps,其余配置无需更改点击确认增加链路。
点击“控制台”,进入虚拟机登录界面shadowrocket4g网络,使用“root”账户登陆,密码见上述界面,依次输入用户名“root”及密码即可进入虚拟机。


