ps4 shadowrocket


在企业级 AI 的落地周期中,存在一个极其吊诡却普遍的现象:很多企业花重金微调并部署了一套堪称完美的智能体系统,上线首月好评如潮;然而仅仅半年后,业务部门却纷纷抱怨系统“越来越听不懂人话”、“总是拿旧规矩办新事”。为什么寄托了企业厚望的 AI 并没有像科幻电影里那样“越用越聪明”,反而不可逆转地走向了衰退?很多企业买大模型,以为买的是一个全知全能的成品,但在真实的系统工程学中,出厂的模型仅仅是一个“胚胎”。作为深耕成都及西南制造业与政企 AI 架构的逐米时代,我们始终向决策者灌输一个极其冷酷的真相:决定企业 AI 最终商业高度的,不是你第一天导入的预训练参数,而是你是否在底层构建了一座生生不息的

图 1:如果不建立动态的纠错流水线,AI 的智力水平将在上线的第一天达到巅峰,随后直线下滑
要理解 AI 为什么会变蠢,我们必须引入机器学习中一个极其核心的病理学概念:概念漂移(Concept Drift)。
在控制论(Cybernetics)的奠基人诺伯特·维纳看来,任何一个能够持续适应环境的系统,都必须具备接收外部“误差信号”并自我修正的机制。然而,当你把一个开源大模型下载到本地,或者完成一次昂贵的私有化微调(SFT)后,这个模型的几十亿个参数权重(Weights)就被物理冻结(Frozen)了。
但真实的商业世界是狂奔的。三个月内,你们公司可能发布了两款新产品,财务部修改了出差报销的审批额度,研发部弃用了一个旧的 API 接口。环境(Data Distribution)发生了剧烈的漂移,而模型依然固执地用半年前的“旧地图”去寻找今天的“新大陆”。于是,它给销售报错了新产品的价格,给程序员补全了已经废弃的代码。在动态的商业熵增面前,静态模型的“变蠢”不是一种可能,而是一种必然的数学宿命。
很多软件外包公司为了解决这个问题,给出的方案极其敷衍:在 AI 回答的对话框下方,加上一个“��(赞)”和“��(踩)”的按钮,号称这叫“人类反馈强化学习(RLHF)”。
这在严肃的软件工程中简直是自欺欺人。原因有二:第一,极低的召回率。在真实的、高压的业务操作中,没有哪个员工有闲情逸致每次都去给 AI 的回答点赞或点踩。这种显性反馈(Explicit Feedback)的收集率通常不到 1%。第二,极低的信息熵。就算员工点了一个“踩”,系统依然不知道 AI 到底错在了哪里——是金额算错了?还是语气不够礼貌?仅仅一个布尔值(True/False),根本无法为庞大的神经网络提供修正梯度的方向。
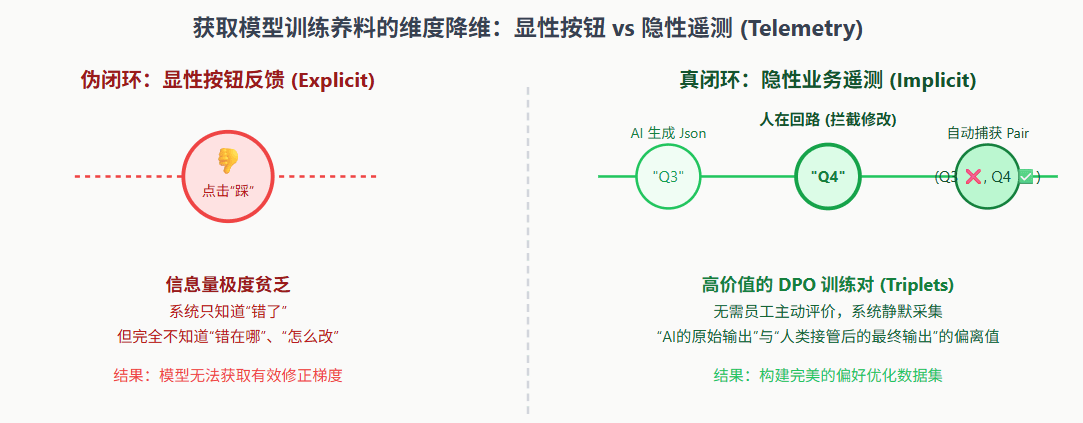
工业级的智能体系统,其智慧的源泉来自于深埋在架构底层的**“影子日志系统(Shadow Telemetry)”**。它不要求用户打分,而是像幽灵一样静默地捕获用户在业务系统中的一切“修正动作(Correction Actions)”。
回想我们在第 22 天讲过的“人在回路(Human-in-the-Loop)”机制:当智能体生成了一份财务退款工单,人类审核员发现金额不对,手动将系统填写的“5000元”修改为“4800元”,然后点击了通过。
在传统的软件里,这件事就结束了。但在搭载了数据飞轮的 AI 架构中,真正的炼金术才刚刚开始。底层遥测系统会瞬间捕获三个关键变量,打包成一个极其珍贵的训练三元组(Triplet):
这种格式的数据,正是当前大模型前沿微调技术DPO(Direct Preference Optimization,直接偏好优化)最完美的燃料。它不仅告诉了模型正确答案是什么,更通过(Chosen Rejected)的数学梯度,明确地告诉了神经网络:“人类更偏好这种逻辑路径,你要抑制那种导致 5000 元的错误推演。” 这种高质量的业务隐性反馈,每天都在企业的日常运转中海量产生。
但是,有了 DPO 数据,如果依然靠人工每个月去拷贝日志、清洗数据再手动启动训练脚本,这种高昂的运维成本依然会拖垮企业。真正的数据飞轮,是一条由代码驱动的无人工厂。
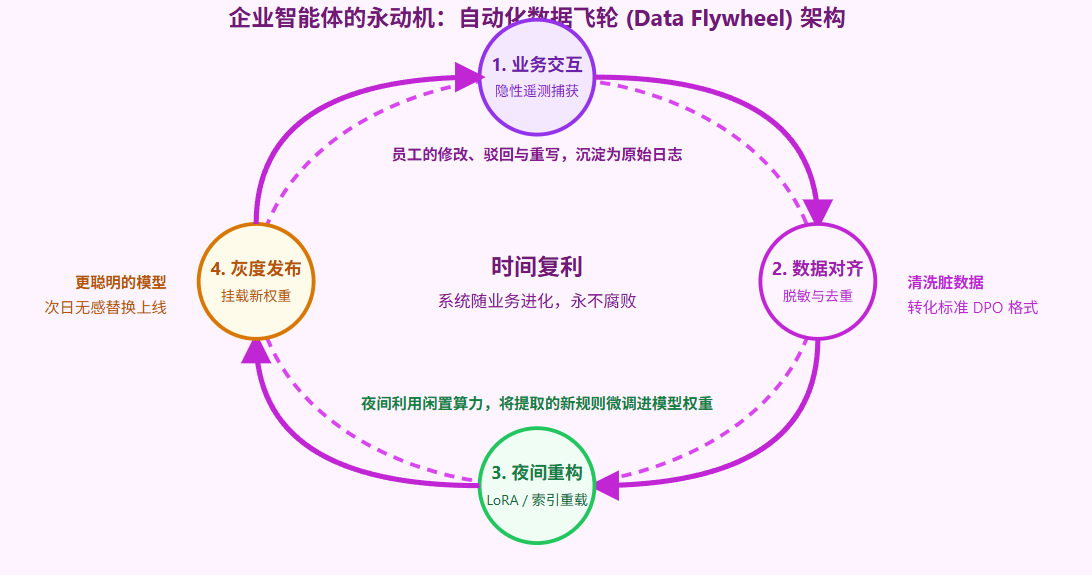
逐米时代在为企业设计这套架构时,极其注重流水线的无人化干预。白天,全公司的员工在使用智能体时产生的修正行为被静默收集入数据湖;深夜,当企业算力集群闲置时,自动触发清洗脚本(剔除异常数据),然后调用LoRA(低秩自适应微调)算法,用极低的算力成本对模型权重进行局部更新,或者触发知识图谱的向量重构。第二天清晨,员工上班时面对的,就是一个已经自动吸收了昨天所有错误教训的全新系统。
· 成都及西南地区非标自动化与柔性制造企业:产线的工艺参数、物料配比几乎每个月都在随着新订单调整。如果智能体不能自动通过质检员的修改日志来更新自己的判定阈值,模型一个月内就会因为报错率过高而被产线弃用ps4 shadowrocket。
· 电商客服与出海售后中心:竞品策略和营销活动瞬息万变。今天的新爆款,明天的售后规则就变了。必须利用客服主管的“话术修改记录”自动驱动大模型进行微调,才能保证 AI 的口径永远和公司战略同频。
· 深水区的专业咨询与法律服务:判例和法规的变更是持续的。律师在智能体生成的初稿上划掉的每一行废话、补充的每一个法条,都是极其昂贵的专家知识,必须被底层捕捉并内化为系统的通用能力。
在古典的软件工程时代,项目的“上线”意味着交付的终点,接下来的岁月只有无尽的维护与修补。但在生成式 AI 的纪元,把一个模型安装到服务器上,仅仅是一个极其微小的开始。
企业真正应该追求的壁垒,不是买到了全宇宙参数最大的预训练模型,而是你是否在内部建立了一条能够持续榨取业务经验、反哺系统智力的封闭管线。逐米时代在私有化 AI 架构的深水区里,拒绝只做“一锤子买卖”的模型搬运工。我们深入企业的业务血管,致力于为您搭设这套包含隐性遥测、清洗对齐与自动化微调的工业级数据飞轮。让您的系统不再是对抗时间腐烂的消耗品,而是随着业务的深耕,像极具智慧的老员工一样,与企业共同生长,享受认知积累的复利狂飙。返回搜狐,查看更多