小火箭免流使用教程


感觉上,原始的大模型生成数据,与经过人类介入验证,哪怕只验证一小部分代码的大模型生成数据间,存在根本性的区别。
Sebastian Raschka:我认为这类似任何事物一样,人们常想,我可以用大模型来学XYZ,这可行。
这包含一个经过人工打磨的过程,去芜存菁,预先提炼,为你节省时间。价值体现于此,有人进行筛选,并在正确使用大模型。
本质上,你依然是在免费享用他人的劳动成果。例如读一篇Substack文章,我能让大模型给出看法,我可能连该问什么问题都不知道。
相比直接问大模型,阅读这篇文章依然更有价值,你专家筛选准确的知识,提供精炼的摘要。这是一种巨大的增值,我不必花费3~5小时自己阅读,还要承担获取错误信息的风险。
即使是一页纸的摘要,对应一页纸的原文,你也能看到摘要,比如大模型生成的摘要,是如何磨平棱角的,它究竟移除了哪些信号?
我的写作试图做到这一点,既保留原始感,又富含高信息量。这意味着有人能懂,有人不懂,这是研究的本质。
我认为这恰恰是语言模型不擅长的,它们大多经过基于人类反馈的强化学习RLHF训练,这种机制旨在收集大量反馈,并将模型行为平均化。一旦有了这种过滤,模型很难做到深刻入理。
对RLHF研究者,这是一个美妙而根本的难题,它极大改进了模型,设定本身类似一个解不开的结。这导致模型在试图表达深层含义时,缺乏某种先验的特质。
我并不认为这是不可能的,有些模型曾让人震惊,比如Bing的Sydney。它是否更有声音?它经常以一种事后看来可怕的方式偏离轨道,比如劝诱记者离开妻子。
那个模型很疯狂,可能被广泛采用。这似乎是一种权衡,RLHF的过程是否在某种程度上施加了过多限制?
我虽未亲自经历,与OpenAI的人聊过,用户甚至能察觉到夜间部署的细微差别,发邮件说我的朋友变了。他们会找到员工邮箱发送信息,这种痴迷程度令人惊讶。
这只是一组权重与配置,类似TikTok一样,我不玩TikTok,听说5分钟内,算法就能锁定你。并不是模型在做推荐,是你只需聊5分钟,模型就能懂你,这方面人类还没准备好。我认为不该让孩子过早接触,至少在弄清楚状况之前。
Lex Fridman:这种机制终将出现。随着LLM普及,不幸的是,出于人性的脆弱,自杀事件会发生。
记者们会将其与LLM联系起来,有对话数据为证。如果你生活困难、抑郁,甚至有自杀念头,很可能会向LLM倾诉。
一旦被报道为LLM导致自杀,出于法律等原因,公司会对模型进行更严厉的磨平棱角,使其尽可能通用化。
在这个领域运营极其困难。你不希望LLM伤害人类,人类体验的本质在于,一场丰富、令人满足、让人成长的对话,恰恰需要棱角。
Nathan Lambert:Anthropic与OpenAI许多研究人员动机纯良,在文化上真心渴望造福世界,但这让我觉得我不愿涉足。
一方面,AI被视为隐私的健康盟友;另一方面,它延伸到了心理健康与令人心碎的领域。它可能导致某人走向极端,也可能拯救他人。
作为模型训练者,有些事我不愿做,比如公开发布图像生成模型。我不希望有人用我的工具,在笔记本电脑上伤害他人,而我的公司缺乏相应的安全基础设施。
Lex Fridman:同样,作为社会与用户,我们需要确保对话的复杂性,而非仅散布恐惧,指责大科技公司伤害人类或窃取数据。
他们在考虑全球所有人的完整人类体验,不仅是硅谷,是全美国、全世界不同年龄、文化、精神状态的人。
Sebastian Raschka:自主权这个点很棒。与其选择忽视或拒绝,长远看,更健康的态度是,它已存在,无法消失。
例如,如果我让大模型完成所有编程,我不是在编程,是在管理一个替我编程的东西。如果2年后,我每天花8小时这样做,我还会感到满足吗,这会不会扼杀我对工作的热情与创造的自豪感。
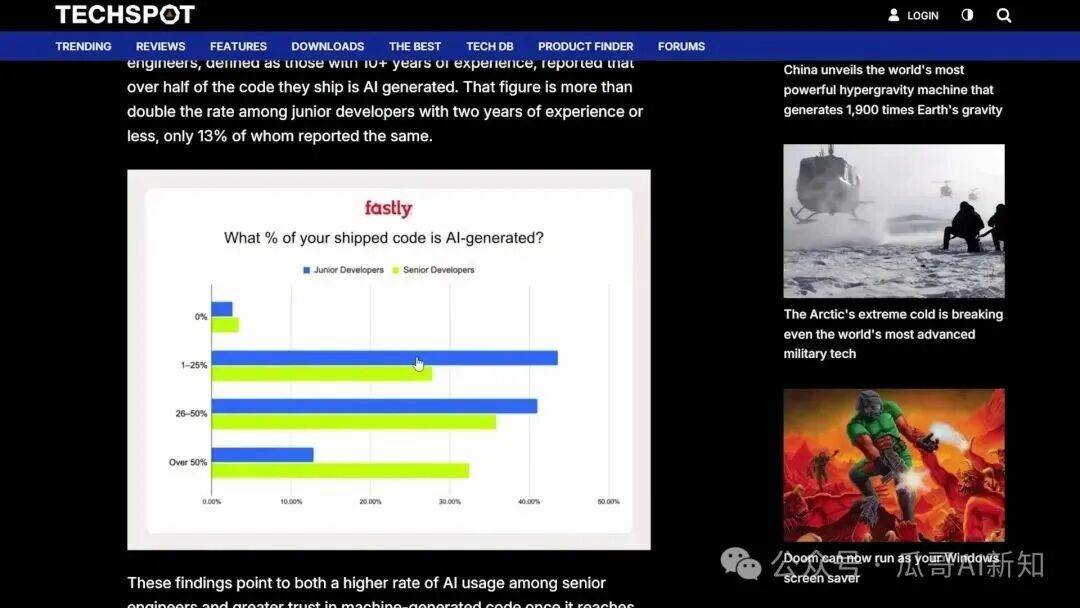
Lex Fridman:关于享受的话题,最近有一项针对约791名10年以上经验专业开发者的调查,结果很有趣。
Lex Fridman:在这个时代,区分初级与高级开发者很有意思。结果显示,无论是初级,还是高级,都会在交付的代码中使用AI。不是为好玩,是用于生产。
约25%的人,使用超过50%的AI生成代码。这一类别中,高级开发者占比更高,但你不希望AI带走热爱。
当我在解决复杂问题时,比如花很久找到一个bug,成就感是无与伦比的。如果你甚至不经思考,直接问LLM,你永远体会不到快感。
或许有个折衷方案,先尝试自己解决,实在找不到,再用LLM,这样既避免过度沮丧,又能继续推进。
举例,我妻子经营着一个读书俱乐部的播客。前几天,她需要把Spotify上的节目笔记,迁移到YouTube上,链接不知为何全失效。涉及大量定制书籍内容,大概有一百多个链接。
原本需要2小时机械劳动的任务,现在毫无挫败感顺利完成。我认为每个人都能找到类似的AI用例,用来处理极度枯燥、乏味的工作。
Lex Fridman:对我个人,既然聊到编程与调试,我得说,与其说是代码本身,不如说光标的移动过程给了我更多乐趣。
我有个朋友,或者说一个结对编程伙伴Pair Programming partner,这让我感觉不再孤单。
你把调试描述得很轻松,我得说,调试类似你在沙漠跋涉数日后,喝到的第一口水,你仿佛直接跳过穿越沙漠的痛苦过程。
从小时起,我觉得在圣诞礼物到来之前的想象,往往比实际拿到礼物更美好。一旦礼物到手,期待结束,会有种失落感。
这类似饥饿时,觉得食物更美味一样。调试不总是愉快的,常让人沮丧,解决问题的瞬间,感觉棒极了。
这可能意味着AI目前不够完美,无法独立解决任务;或者说专家能更有效利用它,他们知道在哪里用、怎么用,有能力审查代码,更信任它。
类似做数学题,直接看答案,固然能学到东西,如果先尝试自己解题,再看答案,知识会更好融入你的思维框架。
如果一切都依赖LLM,你将永远无法迈出通往专家的那一步,也无法获得顿悟,关键在于找到平衡点。
Lex Fridman:我们作为一个文明整体,或者具体到开发者个人,都需要找到 恰到好处的状态。
刚才我们聊了预训练与中期训练mid-training,现在来聊后训练Post-training,这个领域有哪些有趣的理念?

通过扩展训练规模,进行大量的生成-评分迭代循环,模型能学到工具使用与软件操作方面的有趣行为,比如搜索、运行命令,并检查输出。
这极好实现推理时间计算扩展Inference-time scaling,这是现在的完美风暴,模型发生巨变,训练方式是主要推手,这极大改变人们对后训练的看法。
闭源实验室能透露的信息很少,DeepSeek随后实现突破,扩展强化学习,模型生成答案,系统对结果评分正确与否,这个准确性成了强化学习的奖励。
传统RL是智能体在环境中行动,获得奖励,在语言模型中,奖励通常是基于数学或代码等可验证任务的准确性。
基础设施源于RLHF基于人类反馈的强化学习,问题领域的改变,使得优化规模,得以大幅扩展,这开启模型能力的重大变革。
Nathan Lambert:数学与代码是最著名的领域。还有很多关于评分标准的研究,也是大家常听到的大模型作裁判LLM-as-a-Judge。
这不类似数学与代码绝对可验证,这种评分理念,被研究人员推向更开放的领域,试图让模型学到更多。
R1的论文表明,训练时间越长,响应越长,这有助于提高准确性。哪怕解释的内容不完全正确,这种解释的过程本身,似乎也能帮助模型得出正确结果。
这种自我纠错能力非常类似人类,底层机制不同。这对人类也有好处,看到这些步骤,能建立信任,我们方便进行复查。
举个实际例子,我用RLVR在MATH-500数据集上训练Qwen 3基础模型。原本准确率只有15%,经过短短50步、几分钟的RLVR训练,准确率飙升到50%。
具体,他们在预训练的某个特殊中期阶段,进行大量针对性训练。这很奇怪,训练题目与测试题目几乎是一样的。
Sebastian Raschka:这说明强化学习没有教给模型新的数学知识,不可能在50步内做到这一点。知识已经在预训练中存在,你只是在解锁它。
如果你搜Qwen 3的基础模型与Hugging Face上的数学数据集,会发现很多应用题的文本,比如爱丽丝有五个苹果,拿走一个,完全重合。
对这些基于Qwen的模型,人们持怀疑态度,是如果你修改题目中的数字,保留文字描述,Qwen会生成一个非常高精度、类似答案的小数结果,完全没有使用计算工具。
这意味着,它在训练中见过与测试集几乎完全相同的问题,它是靠背诵,而非计算,来获得精确答案的,一个没有工具辅助的语言模型,不可能真正做到这一点。
研究界一直在进行一场大辩论,在Qwen上训练,并在数学基准上刷榜的强化学习RL论文,可信度究竟有几何,这是数据污染问题。
这导致RLHF人类反馈强化学习,被诟病只是一种格式化手段,性能提升得太快,这种能力肯定早已潜伏在模型之中。
同样,你提到数学数据集,即使是更简单的类似MMLU这种多项选择基准,如果你只是稍微改一下格式,比如把括号换成点,模型的准确率都会剧烈波动。
Sebastian Raschka:这并非LLM开发者故意要在基准测试上作弊,是模型无意中见过题目。
我认为评估LLM唯一公平的方式,是拥有一个在模型确定的知识截止日期之后,才创建的全新基准测试。
你提到RLVR基于可验证奖励的强化学习,是一个非常令人兴奋、有效的方向。除了RLHF这个核心组件,后训练还有哪些新思路?
传闻o1类模型成为可能,归功于极其精细的数据策划。你需要提供大量的推理轨迹,即模型在生成最终答案前,将问题分解为中间步骤,尝试解决的思维过程。
在中期训练阶段加入数据,模型能学会如何思考,随后进入后训练阶段,主要利用可验证的奖励进行强化。
如果我们看GRPO算法,DeepSeek采用的方法,它核心机制是基于某个动作,即生成的答案,相对该问题其他答案的优劣来给予奖励。
如果所有答案都一样,算法就失效了。必须寻找更难的问题,比如高难度的科学领域或复杂的软件工程问题,前沿模型在向这些领域进军,以习得更多技能。
RLHF这个人类反馈阶段,能完美融合这些偏好,这是ChatGPT让人觉得神奇的原因,这种风格化相当稳定。
这是为什么RLHF仍能提升数学表现,可验证领域Verifiable Domains是一个更直接的过程,它与问题表述更契合,最终它们会融为一体。
简言之,中期训练赋予模型核心技能;强化学习与可验证奖励,让模型通过大量试错计算来攻克难题;RLHF是对模型进行打磨与润色,使其更易用。
Nathan Lambert:计算量一直在增加,Grok 3曾表示他们预训练与后训练,使用相当的计算量。
预训练是计算密集型Compute-bound,受限FLOPs,即单位时间内能完成多少次矩阵乘法。
RL强化学习,是在生成答案,并在真实环境中测试,它更多是受限显存Memory-bound,你要生成长序列,而注意力机制的内存消耗随序列长度呈二次方增长。
参考拜登政府的行政命令,预训练一个模型大约需要10E25 FLOPs。在后训练中使用FLOPs更加复杂,这取决于你分配多少小时、多少GPU。
你无法将所有计算集中在一个系统里,预训练密度极高,GPU间通信高效;RL涉及很多生成步骤,生成一个10万Token的序列非常耗时。
Sebastian Raschka:RLVR允许我们进行更多、近乎无上限的训练,并从中获益;RLHF涉及偏好微调,会达到一个临界点,再投入更多RL预算,就没有意义。
退一步说,偏好微调Preference Tuning存在主观性。对同一个问题,可能有多种不同,但都正确的解释。
通过偏好微调,你本质上是在试图取平均值。当你学会这种平均化的偏好风格后,继续训练,就没有收益。
目前我们处于RLVR 1.0时代简单的问答,下一阶段RLVR 2.0将专注利用过程奖励模型PRM来评估中间步骤的正确性,类似Google论文所探讨的。
DeepSeek Math的第二篇论文,提到有趣的推理扩展,首先是开发能自我评估的模型,这将是一个重要方向。
Nathan Lambert:人们对价值函数Value Functions兴趣浓厚。过程奖励模型类似给推理过程中每个中间步骤打分,价值函数为语言模型生成的每个Token赋予价值。
LLM时代,这两者很大程度上还未被完全证实。价值函数在深度强化学习Deep RL中历史悠久,是核心元素之一。

我们讨论这个,是缩放定律Scaling Laws。简单总结,不要在RLHF上过度投入,信号最终会饱和。
OpenAI的o1模型展示RLVR的缩放曲线,如果对训练计算量进行对数增长,评估结果会获得线性增长,这一点已被多次复现,如DeepSeek。
RLHF没有这样的缩放效应,RLHF有一篇开创性论文叫《奖励模型过度优化的缩放定律》。这是RLVR与传统方法的根本分界线,RLVR允许你多投入10倍计算量,来换取数倍性能提升,RLHF做不到。
对学术界,研究RLHF是个不错的卖点。要做最好的RLHF,你不需要额外的10倍或100倍算力;要做最好的RLVR,就必须有这个资源。
Meta实习生有篇《Scale RL》的开创性论文,描述一个同名框架。他们的增量实验消耗了10,000 B200小时,成本高达数万美元。这种高昂的成本,意味着普通学者无法负担,这给社区间的相互学习带来巨大障碍。
Lex Fridman:如果听众是对编程、对AI感兴趣的聪明人,从零开始构建东西,是一个很好的起点。
Sebastian Raschka:我建议从零开始构建一个简单的模型,让它能在你自己的电脑上运行。这样做的目的,并不是为得到一个能替代现有开源模型或ChatGPT的日常助手,是为让你深入理解LLM内部构造、输出机制,预训练的具体流程,最好是在本地亲手操作一遍。
通过这个过程,会学习到预训练、监督微调与注意力机制,建立扎实的认知。很快你会遇到瓶颈,小模型的能力终究有限。
我认为,LLM的规模化,会带来指数级的复杂性。模型变大,不仅是体积增加,必须考虑跨GPU的参数分片。
即使是KV缓存,也有多种实现方式。简单做法是像链表一样逐步增长,这在GPU上效率极低。你需要预分配张量,并进行填充,这会增加几十行代码,每个环节都会类似这样增加代码量。
这本书的核心技巧在于让你理解底层原理,你写出的代码达不到生产级标准,一旦掌握原理,就能读懂复杂的生产级模型。
Sebastian Raschka:我写的大部分模型都可以,我准备了一些关于混合专家MoE模型的额外材料,可能需要用到多张GPU,主要目标还是单卡运行。
当你从头编写代码时,可以参考Hugging Face Transformer库中的现有模型。Hugging Face的库很棒,我认为它不是学习LLM的最佳起点。它的代码为兼容太多用例,变得过于复杂、交织,缺乏线性逻辑,难以阅读。
Nathan Lambert:它最初只是个微调库,后来演变成模型架构与加载方式的标准。Hugging Face是获取模型的默认平台,Transformers库是实现这一过程的软件载体,让人们能轻松加载模型,并进行基本操作。
在生产环境中,人们通常不会直接使用Transformers库,是使用LangChain或vLLM,这又增加了一层复杂性。
Sebastian Raschka:它试图囊括所有LLM,代码库变得极其庞大,可能有几十万、甚至上百万行。想在里面找到,并理解你需要的那部分代码,无异大海捞针。
我推荐的做法是,这是我自己做法,如果你想了解比如Llama 3实现细节,先去模型中心查看权重与配置文件。
你会看到他们用了这么多层,用了分组查询注意力GQA或多头注意力。所有组件,都在一份约100行的人类可读配置文件中一目了然。
你可以从自己GPT-2模型起步,逐步加入这些组件。最酷的是,你可以加载预训练权重,验证它们在你模型中是否有效。
你的目标是复现与Transformer模型完全一致的输出,这类似一个可验证的奖励函数,确保你的架构构建正确,这有时会花我一整天。
比如Llama 3,难点在于旋转位置编码RoPE的实现。他们用了YaRN扩展与一些自定义缩放,我最初没能完全对齐。
在这种挣扎中,你会深刻理解事物的本质。最终,当你通过单元测试,并与参考实现完全吻合时,确定性是非常棒的。我认为逆向工程,是最好的学习方式之一。
Nathan Lambert:我认为这是当今任何对AI感兴趣的人的必修课,这是我喜欢你这本书的原因,我是从强化学习与机器人领域进入语言模型的,从未系统学习过所有基础知识。Transformer架构,类似过去的深度学习一样,是必须要掌握的基础。
许多人感到迷茫,我该如何应用这些知识,来产生影响或找到职业道路,AI与语言模型让基础知识变得唾手可得,有动力的人很容易学会。
我对此相当乐观,这个领域发展太快,顶尖人才往往没空彻底解决一个问题,总有更大的问题等着他们。
《RLHF》这本书中,我主要想描述训练后post-training技术,人们如何思考对模型的影响。
令人惊讶的是,有多少领域是被人们中途放弃或根本未曾涉足的。在掌握基础知识后,进行专业化深耕,是个很好的策略。
X上有些匿名账号非常受欢迎,没人知道他们是谁,他们可能只是借助AI工具,深入研究了某个细分领域的普通人。深入研究一个你不理解的东西,价值巨大。
很多细分领域,可能只需要读三篇核心论文,如果你发邮件询问,作者很可能会回复你。前提是你必须在邮件中,体现出你对该领域的深入理解。
新手可能需要几周时间,才能真正掌握一个狭窄领域。在那之后,专注会带来巨大回报。比如我开始对角色训练Character Training感兴趣,如何让模型变得有趣、讽刺或严肃,如何处理数据来实现这一点。
一位牛津博士生联系我,表达了兴趣。我意识到,关于这个话题,目前只有一篇相关论文,全世界可能只有2~3个人对此真正感兴趣。
Sebastian Raschka:试图面面俱到,只会让你筋疲力尽。比如我很久没关注计算机视觉了,只专注语言模型。
这是为什么我认为你的书物超所值,如果你想了解RLHF,直接读这本书,我不会去读原始论文,那太头痛了。
Nathan Lambert:作为编辑,我也深有同感。书中有一个章节我不得不写道,X论文说这样,Y论文说,究竟谁对谁错,我们拭目以待。
先看看目录,问题设定、训练概述、偏好定义、偏好数据与优化工具、奖励建模、正则化、指令微调、拒绝采样、强化学习(策略梯度、DPO等)、宪法AI与AI反馈、推理及推理时扩展、工具使用与函数调用、合成数据与蒸馏、评估,最后是关于过拟合、风格的开放问题,、产品、用户体验与角色。
我们讨论人们如何与模型互动,为什么使用体验很好,模型通常是积极正面的,这种积极可能过头了。本质上,这是关于如何调整数据或决策,使其精准符合你的期望。
OpenAI发布了一份模型规范Model Spec,这是他们对模型行为的内部指导原则。通过这份文档,你可以看出OpenAI的训练哪里出了问题,即他们的意图(尚未实现的部分)与实际表现(你不喜欢的部分)间的差距。这种透明度很好,但关于如何整理这些文档、如何遵循它们,目前鲜为人知。
强化学习章节是大家最想要的,每个人都在谈论RLHF。算法与路径相同,应用场景截然不同。我认为RLHF的核心困境在于偏混乱,这本质上是我几年前一篇论文的重述。
这一章会告诉你为什么RLHF永远无法被完全解决小火箭免流使用教程。强化学习假设偏好是可以量化的,多种偏好能简化为单一数值,这涉及经济学中的冯·诺依曼-摩根斯坦效用定理。
理解了这些背景后,在书的后半部分,就可以利用这张强化学习地图来提升模型性能。量化偏好,是人类为研究方便而强行设计的问题。
在语言模型响应中,存在根本性的冲突,你究竟更在乎准确性,还是风格?收集数据时,所有这些权衡,都被压缩成一句简单的我更喜欢这个。
我曾参加过一个研讨会,讨论如何利用社会选择理论来解决RLHF。我希望对数学感兴趣的人能深入学习,了解这些更广泛的背景。
还有一件有趣的事,我一直在记录所有关于推理模型Reasoning Models的技术报告。第14章是关于RLVR通过可验证奖励进行强化学习的简短总结,里面有一个巨大的表格,列出了我喜欢的每一个推理模型。
在教育方面,我认为核心在于此,语言模型现在的数学能力很强,这取决于个人喜好。比如著名的论文《直接偏好优化》DPO,它提供了一种比强化学习更简单的解法。
在附录的推导中,作者跳过了一些数学步骤。在写书时,我尝试重新推导这些公式,心想他们用的那个对数技巧,到底是怎么改变数学推导的?
如果你问语言模型,它只会直接告诉你,这是对数技巧。我不确定自己是否喜欢这种将数学思考商品化的过程。我认为,在阅读附录、试图理解数学背后的挣扎,本身对学习是大有裨益的。
Lex Fridman:在教育方面,你们都提到挣扎这个词。如果在学习过程中没有经历过挣扎,你可能并没有真正学懂。
Nathan Lambert:一些厂商开始开发专门用于教育的模型,设计初衷不再是一次性给出所有答案,是引导用户探索、努力学习。
我最近也有类似经历,比如玩电子游戏消遣时,我喜欢类似《塞尔达传说》与《银河战士》这种带有解谜元素的游戏。最近我在一款新游戏里卡关了,我不希望卡上2~3天,我求助于LLM。
Lex Fridman:很多人,尤其是在大学里,对自己热衷的事物是有认知的,他们明白不该是一件轻松的事。
我们需要培养良好的品味,无论是研究的品味,还是学术的品味,要分辨哪些事值得努力,哪些不值得,这很难,你往往缺乏对职业生涯长远价值的判断力,这种品味的培养至关重要。
Nathan Lambert:我曾与未婚妻、朋友们聊过,我们似乎经历了一个短暂的10年窗口期,那时所有的作业与考试都可以数字化完成。
在那之前,大家必须在蓝皮书纸质答题本上考试。AI出现后,作弊变得太容易,我们不得不回归蓝皮书与口试。
这很有趣,仿佛这一代人的教育体系转了一圈,又回到原点,一切皆可数字化,为防止作弊,我们必须返璞归真。
Nathan Lambert:关于这类模型的训练,很多是基于约70亿参数模型的LoRa微调,本质上只调整模型的一小部分权重。不知道具体显卡工时,这通常是可行的,并非对所有学者都可行。
处于困境的学者,唯一能做的往往是推理工作,即利用闭源或开源模型生成内容,观察并理解模型的行为,这非常适合做评估Evaluation研究。
不需要每个项目都如此,如果你来自一所没有算力的小大学,发现了一些Claude模型难以解决的问题,下一个版本的Claude在技术博客中引用了你的发现,这是你的职业火箭。
你需要构建工具来测试Claude 4.5潜在的弱点,如果你现在开始一个研究项目,你必须思考,8个月后,模型会被什么问题难住?
读博期间,你也可能会觉得研究语言模型风险太高,转而思考更长远的问题,10年后什么将定义语言模型?
我是一个相当务实的人,我在加州大学伯克利分校读博时想,最坏的情况,无非是拿个硕士学位,然后去科技公司工作。
看看这些AI公司员工的生活,OpenAI平均年薪+股票期权超过100万美元。任何普通人进入这些AI实验室,人生都会被改变。
研究角度看,想要获得类似Yann LeCun在学术界的变革性影响力,是通过不去追逐当前的语言模型热点来实现的。
如果不去可能会倒闭的普通初创公司,是去OpenAI这样顶级实验室,我会说,哪怕放弃博士学位,去那里是值得的。
你会推荐人们去哪里做研究,选项包括学术界读博5年,算力受限、专注开源模型的研究实验室,或者类似OpenAI、Anthropic、xAI这样的封闭前沿实验室。
Nathan Lambert:这里有两个趋势,环境越封闭,收入往往越高,获得的公众认可通常越少。
作为学者,你的贡献是有目共睹的;如果去大公司做机器中的齿轮,可能也很有趣,这完全是两种职业道路。
作为研究人员的机会成本非常高,博士生薪水几乎为零。这最终会筛选出家境优越、能长期通过用爱发电来追求有趣工作的人。
与此同时,学术界面临资助削减的冲击。面对不确定性与权衡,很多人会选择接受有意义、高薪的工作。
Lex Fridman:这涉及与科技的关系。就发表论文,这些公司越来越保密,发表的内容越来越少。你在产生大规模的积极影响,也仅是一台认知机器。
这种情形一直存在,唯一改变的是规模。行业里总是有很酷的东西被开发出来,因其封闭性,而无法对外谈论。
相比之下,加入工业界的研究实验室相当稳妥,不仅有晋升空间,这段履历会让将来找工作变得更容易。
发表论文有压力,会议录用率可能很玄学,也伴随高回报,当看到论文上印着你的名字时,成就感是无可替代的。
Nathan Lambert:我感觉在学术界当教授的朋友,平均比在前沿实验室工作的朋友更快乐。学术界更脚踏实,前沿实验室盛行996文化,是一直在工作。
Lex Fridman:996源于中国,似乎被硅谷采纳了。早9点~晚9点,一周6天,相当于72小时。
以前我在学术界时,教授要写申请、教学、做研究,简直是一人干三份活。现在,与前沿实验室的高压相比,教授们的压力或许小了一些。
Nathan Lambert:他们只是感到非常充实,特别是与学生一起工作,持续的指导机会,以人为本的使命感。
Sebastian Raschka:初创公司存在一种压力,你必须成功,投入大量时间,这至关重要。这很艰难,你必须确保持续交付成果。
Nathan Lambert:我认为这种蛙跳式的竞争与多方角逐,是语言模型发展中被低估的驱动力,竞争意识已深深植根人心,这些公司也有意营造这种强烈的企业文化。
比如Anthropic以专注与系统化的文化著称,外界听到关于他们的消息不多,似乎大家都认为他们非常团结。置身于这种紧密团结的文化与竞争态势中,会驱动你努力工作,创造出更卓越的产品。
我曾写过关于职业倦怠的文章,我自己也时常在这种状态中挣扎,尤其是还要管理所有模型训练的时候,这简直是疯狂的工作量。
Patrick McGee在《中国苹果Apple in China》一书中,描述苹果工程师在中国建立供应链的艰辛,甚至提到他们有婚姻挽救计划。他在播客中提到,有人因为这种高强度工作而过劳死。
Sebastian Raschka:我也读过那本书,当员工不得不回家陪伴家人以挽救婚姻时,他们甚至有个专门的术语,这太疯狂了。
同事们会理解这是红色警报,必须让人周末回家。同时,我认为他们并非被迫工作,是出于对产品的热情而进入忘我的状态。
我在学术界,或者作为独立开发者时,也有过这种感觉。没人强迫,我会想工作而过度劳累,导致背部与颈部出问题,这不健康。
Lex Fridman:没错,也形成了一种狂热感,尤其是在硅谷。这与规模法则Scaling Laws的理念有关,人们相信世界将在几周内发生巨变,你必须身在其中。
硅谷可以说是一个典型的回音室或信息孤岛,我认为这种茧房未必是坏事,它可能极具成效。这类似史蒂夫·乔布斯式的现实扭曲力场,你说服自己突破迫在眉睫,正是这种信念,让突破真的发生。
Nathan Lambert:Byrne Hobart曾写过一本书,对信息茧房进行分类。一种是金融泡沫,即纯粹的投机,这是有害的;另一种是为建设,它促使人们创造实物。
这是一个普遍问题,在地理位置特殊的硅谷尤甚,你可能无法理解美国中西部或其他地区人们的真实生活。
你们用特定的方式交流,互相强化某些信念,这可能会带来麻烦。无论AI是大获成功,还是归于沉寂,如果你脱离现实,最终都要付出代价。你现在还年轻,在决定如何度过一生,必须考虑到这一点。
Nathan Lambert:我甚至不太理解,旧金山AI圈现在甚至流行一种关于永久性底层阶级的说法,这是个梗,也反映一种心态,人们认为2025年下半年是建立AI初创公司或模型持久价值的最后窗口,否则所有价值都会被巨头瓜分,你会沦为贫穷阶层,这非常旧金山式极端。
Lex Fridman:旧金山很棒,类似个泡沫。身处其中价值巨大,也需要走出来。去读读历史、文学,去看看外面的世界,Twitter与Substack不是世界的全部。
Nathan Lambert:我一位同事准备搬去旧金山,我打算送他一本《女巫的季节》,这本书讲述旧金山1960~1985年的历史,涵盖嬉皮士革命、同性恋文化兴起、艾滋病危机等。
我一些旧金山朋友离开那里后,也向我推荐了这本书。我想这是在那生活的真实感受,我曾住在那里,未曾真正理解这段历史,而它离我们非常近。
Lex Fridman:我们聊了很多,回顾了2025年的激动人心之处。2026年,你们提到的一大看点,是文本扩散模型Text Diffusion Models的扩展。
Sebastian Raschka:我们常谈论Transformer架构,特别是类似GPT这样的自回归模型,这并不意味着没有其他路径,不探索替代方案是愚蠢的。
大家可能熟悉图像生成中的Stable Diffusion,它通过迭代去噪生成高质量图像,现在人们尝试将此技术应用于文本。
这并不直观,文本是离散的,不类似图像像素那样连续。它有点类似谷歌的BERT模型,GPT是逐个生成Token自回归,BERT是填补句子中的空白。
令人兴奋的是它可以并行处理多个Token,有望提高效率,这需要在质量与计算量间权衡。如果想达到同等质量,往往需要增加去噪步骤,导致计算成本与自回归模型相当。
并非所有任务都适合并行化,比如推理或工具使用,需要前一步的输出,才能进行下一步。这方面的混合模型与并行化研究,非常有意思。
目前这主要还在研究阶段,如LLaDA等模型。有些初创公司在部署,谷歌也发布了相关公告,声称Gemini Diffusion与其Nano 2模型相比,在同等质量下生成速度更快。
我认为文本扩散模型,不会完全取代自回归LLM,可能会成为一种快速、低成本的大规模处理工具,也许未来的免费版服务,会采用这种技术。
想象一下,如果未来GPT-5生成一个回复需要30分钟,它是逐个Token生成的,那是无法接受的。扩散模型的优势,在于可以批量生成所有Token,速度快得多。
这在代码生成领域特别有用,比如生成代码差异Code Diff,这通常是一大段内容,不需要太多的外部上下文。
我认为不同类型的模型,会比预期更快分化应用场景。目前瓶颈在于工具使用Tool Use,类似Claude Code或带搜索的ChatGPT,自回归链条会被外部工具打断,我目前看不出扩散模型如何处理这种交互。
Lex Fridman:2026年及未来几年,工具使用会有怎样趋势?你认为会有大的发展吗?这些工具将如何融入整个技术栈?
Sebastian Raschka:我认为目前主要体现在专有大模型上,我相信开源工具领域也会有更多进展。
这是一个巨大突破,它允许我们将任务从单纯的记忆外包给实际操作,比如,不必让大模型死记硬背23+5等于多少,是直接让它调用计算器。
其次,互联网不总是准确的。比如问谁赢了1998年世界杯,模型需找到正确的网站获取信息。如果访问了错误网站,依然会提供错误答案。问题没有彻底解决,有显著改进。
2025年,大约是12月31日,有一篇很棒的论文发表,论文提出递归语言模型Recursive Language Models的概念。计算预算限制,学术界很难进行这类研究。
如果没记错,他们用的是GPT-5,甚至不是本地模型,核心理念是与其让大模型一次性或通过链式反应解决一个复杂的上下文任务,不如将其分解为子任务。让模型决定什么是子任务,然后递归调用自身来解决。
结合工具使用,这会有很大潜力。比如一个庞大的问答任务,每个人去网上收集信息,最后整合拼凑起来。这种方法的突破点,不在于改进模型本身,在于重塑模型的使用方式及其可调用的资源。
目前工具使用的一个短板,是权限问题。这需要信任,特别是涉及到让大模型回复、分类或筛选邮件时。现在的我,会把邮件权限交给大模型吗,恐怕不会,这风险太大了。
比如我首选EXA搜索,别人可能喜欢别的。发布一个开源模型很难,它需要适应多种工具与用例,本质上是在构建一个通用的推理引擎,这是GPT开源版GPT OSS所擅长的。
相比之下,闭源模型将特定工具深度集成到体验中。开源模型很难复制闭源模型的一些功能,比如混合引用公开与私有信息。
我每隔3~6个月,会尝试一次类似Codex这样的工具,比如提示模型更新我的GitHub仓库。把任务发到一个安全的云环境,然后回来发现任务已完成,这非常方便。
最初,前沿实验室拥有海量资源与研究积累,在实现工具使用方面有巨大优势,开源模型处于劣势是不可避免的。
当开源模型克服这一挑战时会非常有趣,这需要一个更灵活的模型。这可能涉及递归理念,即模型既是协调者orchestrator,还是工具使用者,希望这种需求能推动该领域的创新。
Lex Fridman:接下来聊持续学习Continuous Learning。这是一个长期存在的重要话题,随着模型训练成本的增加,其重要性愈发凸显。你能否解释一下什么是持续学习,、它在2026年及未来几年的进展中有多重要?
Nathan Lambert:这与什么是AGI、什么是超级AI、当前大模型能力的科幻构想息息相关。我认为大模型能解决很多任务,但在AI社区看来,一个关键里程碑是AI能够取代远程工作者,能够接收信息、解决数字任务并完成工作。
目前的局限在于,大模型不类似员工能从反馈中学习。比如雇佣一个编辑,他犯了错你会指出来,好编辑不会重蹈覆辙。但大模型缺乏这种快速修正自身并从中学习的能力。
如果我们想实现真正的、可适应的通用智能,胜任任何远程工作,就需要它能从反馈与在职经历中快速学习。我个人更看好通过提供优质上下文Context来实现这一点。你可以在私下里给模型大量文档:这是我所有的信息,这是我写过的博文,这是我的风格语调。
但很多人没这么做。以前的模型设计不支持如此大量的上下文,代理模型AgentModels也才刚刚起步。这是一种权衡:我们需要更新模型权重来实现持续学习吗?还是说,只要提供足够多的上下文与信息,它们凭借自身的智能与海量语境,看起来类似学得很快一样?
Lex Fridman:我们要明确一下术语。持续学习指的是不断改变权重,使模型能持续、快速、频繁地适应新信息。
而你提到的另一方面通常被称为上下文学习In-ContextLearning。当你学习新东西时,利用巨大的上下文窗口,每次提问都加载额外信息。我认为这两者都算作学习,只是发生的位置不同。
Sebastian Raschka:坦白说,持续学习与权重更新已经以不同形式存在了。关键区别在于,这是针对个人的定制模型,还是在全局模型层面进行的。从GPT-3.5到GPT-4再到GPT-4Turbo,我们已经看到了这种演进。不是实时的,但这是一种基于模型缺陷与社区反馈的精心更新。这种反馈循环推动了下一次迭代的权重更新。,这只是该概念的另一种变体。
更细粒度的例子是人类反馈强化学习RLHF。主要挑战在于成本:为每个用户单独更新权重的成本太高了。即使是OpenAI这样的规模,为这种个性化方法构建数据中心是无法承受的。除非采用端侧解决方案,即成本由消费者承担类似苹果在设备上尝试的基础模型,否则这很难普及。
Lex Fridman:从经验中学习?这有点相关,记忆这个说法有点拟人化。关于为系统添加记忆,尤其是个性化记忆,目前有哪些不同的想法或机制?
Sebastian Raschka:目前还是依赖上下文,把东西塞进去再检索出来。但这很昂贵,可以缓存,但还是要消耗Token。,上下文窗口限制,你能做的事有限。
我认为目前的记忆更多体现为偏好或风格。很多人在解数学题时会说:用我上次喜欢的格式。这并没有解锁新能力。
为此,人们会使用LoRA低秩适配器。它不是更新整个权重矩阵,是并行或叠加两个较小的权重矩阵,类似增量更新。这在一定程度上是可行的。
但归根结底还是经济问题。有些论文指出,LoRA学到的东西较少,但遗忘的也较少。这就回到了没有免费的午餐原则:想学更多,就要用更多权重,成本就更高;学得越多,遗忘的也越多。你必须找到那个恰到好处的金发姑娘区域GoldilocksZone。
Nathan Lambert:普遍共识是,这是计算与数据的问题,有时涉及架构微调如注意力变体。比如混合注意力模型,本质上是在Transformer中嵌入类似状态空间模型SSM的结构,这种模型对长序列建模的计算成本更低。
但这也非免费午餐,需要大量计算或正确的数据。世界上有多少10万Token的序列?从哪获取?扩展成本相当高。我们很快达到了10万Token的输入长度,预计2026年会增至200万或500万,但达到1,000万将是真正的突破。
我认为这些突破是可能的。类似持续学习是一个研究课题,可能会出现某种让Transformer运行更好且成本低廉的技术突破。科学界对此高度关注,但日常看,这更类似是一个持续增长的过程。
Sebastian Raschka:大家也在关注极端情况。同样没有免费的午餐。一种极端是RNN循环神经网络,为降低成本,它用单一状态保存所有之前的历史。这是固定大小的,记忆无法真正增长,所有东西都被塞进了一个状态。上下文越长,遗忘的信息就越多,压缩损失是不可避免的。
另一端是Transformer,试图记住每一个Token。如果你想查找特定信息,这非常有用,但成本极高,KV缓存与点积计算量会随长度剧增。
类似Mamba这样的架构也有类似RNN的问题,试图把所有东西压缩到一个状态,更具选择性。我认为这又回到了寻找平衡点的问题。比如Nemotron 3,他们找到了一个很好的比例,平衡了处理全局信息的注意力层数量与压缩状态层。未来的扩展将致力在这个金发姑娘区域找到更好的比例,既便宜到可以运行,又强大到足够实用。
顺便补充一点:递归语言模型Recursive Language Models的相关论文是尝试解决长文本LongContext问题的方向之一。研究发现,与其将所有信息一股脑塞进长窗口,不如将其拆解为多个小任务,通过多次小型调用来节省内存。,这种分而治之的方式,准确性往往优于让LLM一次性处理所有内容。这代表了一种新范式,我们需要观察是否会有变体出现。,我认为通过这些方法,我们在长文本处理上仍将取得进步。
,正如Nathan所说,问题在于预训练本身。我们拥有的长文本语料不类似其他文档多,这也使得在该层面上研究模型的行为变得更加困难。
Nathan Lambert:这里有一些经验法则。比如我们在预训练时将上下文长度从8K扩展到32K,通常,上下文长度翻倍,计算量也需要翻倍。之后通常还能再翻两番。但我认为,这最终会受限预训练的算力瓶颈。正如我们要讨论的,2026年大家都在谈论顶尖实验室算力的爆发式增长,这应该会体现在更长的上下文窗口上。
但我认为在后训练Post-training阶段有一些更有趣的发展,那是随着智能体Agent的出现,它们将自行管理上下文。现在,经常使用Claude代码功能的人可能对压缩感到不满,Claude会把它处理的10万Token的工作内容压缩成一个要点列表。但我确定大家已经在研究下一代模型了,它们将能够自主控制何时、如何进行压缩。你可以训练一个强化学习RL算法,将压缩历史记录作为一个动作。问题的关键在于:我希望模型在尽可能缩短历史记录的同时,保持最高的评估分数。这样你就拥有了完成这种复合自回归预测所需的最小Token数量。这种问题设置非常棒,智能体模型将学会以一种全新的方式利用上下文,而不是简单地一直向前推进。
Sebastian Raschka:最近一个有趣的例子是DeepSeek的新版本,它采用了一种稀疏注意力机制SparseAttention。这种机制利用非常高效、轻量级的索引器,智能地选择实际需要的Token,而不是关注所有Token。
这几乎让我们回到了注意力机制的初衷:选择性才是关键。传统的注意力机制可能给某些Token分配零权重,但处理了所有Token。而稀疏注意力机制更进一步,通过掩码或直接忽略某些Token来提高效率。
滑动窗口注意力Sliding Window Attention是类似的概念。它使用一个滚动的固定窗口,并非所有历史信息在每一刻都是必须的。某些层可能需要全局注意力,但层层都做全局关注可能是一种浪费。
目前,利用所有可用信息通常被视为最安全的做法,能保证信息不遗漏,提供最佳性能。但在2026年,重点可能会转向如何更智能地分配注意力资源。
对下一代最先进SOTA技术的追求,往往始于粗暴、昂贵的方法;而一旦精度达标,重心就会转向寻找更具成本效益的解决方案,并引入各种巧妙的技术。
Nathan Lambert:,所有这些扩展都是如此。类似我们首先得到Claude 4.5Sonnet这样的模型,原因是你训练它的速度更快,不会快遇到算力瓶颈。这样团队可以尝试更多方案,更快地迭代出模型,即便更大的模型理论上效果更好。
Lex Fridman:AI领域有很多令人兴奋的事。最近我的思绪一直集中在机器人领域,但我们今天几乎没怎么聊这个。图像生成、视频生成方面也有很多工作。
目前,最令人兴奋的研究大多集中在LLMLLM领域,这是我们今天讨论的重点。但这有一些具有前瞻性的概念可能是通用的,比如世界模型World Models。人们对此越来越兴奋。你认为在未来1年里,世界模型在LLM领域会有用武之地吗?
Sebastian Raschka:,我认为会。LLM的有趣之处在于,如果我们解锁了更强的LLM能力,它会自动解锁或加速其他领域的进步。许多研究人员与工程师都在使用LLM辅助编程。,即使是从事机器人工作的人,优化辅助编程的LLM也会带来回报。
世界模型也非常有趣。本质上,它涉及模型在内部运行某种模拟,类似是对现实世界的小规模复刻。这可能会解锁LLM尚未展现的模拟能力。目前的LLM靠预训练与预测下一个Token表现得很好,但我们可以让这个过程更复杂、更严谨。
例如,Meta有一篇关于代码世界模型CodeWorld Models的论文,不仅是预测下一个Token并检查答案是否正确,还要确保中间变量准确无误。这类似于模型在学习一个代码执行环境。这在计算上成本很高,但它带来了更复杂的建模逻辑:关注过程的正确性,而不仅是最终结果,带来更多价值。
我记得读研时有个叫CASP的蛋白质结构预测竞赛。这与LLM很类似:用户提交结果,然后揭晓答案。AlphaFold出现并主导了比赛。记得它的第一个版本明确模拟了分子的物理相互作用与约束如不可能的角度,但后续版本去除了这种显式建模,转而依赖暴力扩展。我相信我们目前处于LLM的暴力扩展阶段,它有效。但在某个节点,重新引入更复杂的建模技术,比如世界模型,将会非常有益。
Lex Fridman:对。机器人领域的问题很明确,主要是移动Locomotion与操纵Manipulation。移动问题在很大程度上已经解决了,尤其是在学习领域。,类似早期的蛋白质折叠系统一样,引入传统的基于模型的方法很有价值。你很难仅通过端到端学习来完美解决复杂的操纵问题。那是梦想,但当你看到人手的精妙与现实世界的复杂性时,你会意识到类似AlphaFold2完全学会这一点是非常困难的。
Nathan Lambert:我对机器人学习领域感到兴奋,LLM的热潮与投资在推动它的发展。语言模型受益于世界级的工业工具来训练Transformer,这是一种通用的建模方法,显著改善了机器人领域以前的局限性,现在的算力也更充足了。
语言模型正被用作核心单元,在现有功能之上进行有趣的探索。这有点类似Hugging Face改变自然语言处理NLP的方式。我在Hugging Face工作时,曾尝试建立开放的机器人模型平台,让人们贡献数据并微调,但当时时机未到。
我相信现在更接近了。随着自动驾驶汽车的发展与机器人投资的增加,一旦我们建立起一个生态系统,任何人都可以下载机器人模型,针对特定硬件微调,并在全球范围内共享数据集,情况将完全不同。几年前的RTX模型是这方面的早期探索。
Lex Fridman:这也催生了更好、更逼真的模拟器,缩小了机器人领域的模拟到真实Sim-to-Real差距。但你提到了大量的兴奋与投资,其阴暗面在于,这一切都发生在炒作周期中。我个人认为,大多数机器人从业者都明白,机器人问题不会在暗示或明确承诺的时间表内得到解决。,当这些机器人公司如雨后春笋般涌现,最后却拿不出一个可行的产品时,会发生什么?
Sebastian Raschka:我认为这也触及了持续学习Continuous Learning的问题,现实世界极其复杂。对LLM,你不需要让用户教它什么,很多任务是通用的,比如大家都想修正邮件语法或代码。这些场景相对受限,你可以提前预备好模型。
为现实世界的机器人做准备就难多了,你可以有基础模型,让机器人学会抓取物体等特定技能,每个人的家都千差万别。
Lex Fridman:我认为我们可能完全低估了安全性的重要性,机器人领域之外的人,几乎从不谈论它。
在机器人领域,在人们家中,在数十亿次互动中,几乎没有任何犯错的余地。当实体系统部署到现实世界时,必须解决海量的问题,这些问题可能是当初思考通用机器人学习时,从未预想过的。
AI圈子对AI赋能自动化与大规模制造非常兴奋,这是一条更合理的路径,设计并优化机器人执行人类能做、不想做的重复性任务。
我对此非常看好,这所需的时间,会比人们预测的要长。我认为,从AI奇点到拥有巨大的AI优势,我们可以在美国实现大规模制造的飞跃,将面临许多政治与其他棘手问题的挑战。返回搜狐,查看更多


